How to organize a remote software development team
Learn how to set up development and quality assurance process for a small remote team

When you are a small company, you are limited with resources — limited with time, limited with money. The most important rule to know in this kind of scenario is the 80/20 rule. Spend 80% of the time focusing on 20% of the most important things. So, in this case, to build upon the shoulders of the giants we need to utilize agile development and lean startup methodologies.
I am responsible for managing a remote team in the sales niche, called Thread.live. We are building a web application that helps salespeople communicate with customers and close more deals. I have managed different kinds of teams in the past but to give you an example, the team at Thread consists of 3 Developers, 2 QA Engineers, a Product Owner, and a Scrum Master.
The tools and methods mentioned in this article are the ones that we use. They are mostly free and simple enough, and the process describes the most important elements to make the project run smoothly with teams of up to 10 people.
💻 Development process
We are using a custom combination of Scrum and Kanban methodology for product development.
A sprint (or iteration) is the basic unit of development in Scrum methodology. We have sprints that last 1 week and each week we have a sprint review and planning call.
We organize our issues into Icebox where all new issues are added. All of the issues that we decide to implement are moved to Backlog. Also, we have the Sprint backlog which includes only the items to be done in the actual sprint. The Sprint backlog is created by assigning the corresponding milestone to the issues in the global backlog.

Development steps
- Items in the backlog are prioritized from top to bottom and should be executed in that order if possible. If the work is started on the issues that don’t have the highest priority, a comment should be added.
- The estimates for the difficulty of the items are done during the sprint planning call. They can’t be changed later during the development, but the estimation can be later discussed in the sprint review. If in a rare case that issue doesn’t have an estimate already but is of high priority, the estimate should be added by the developer before starting work and moving the issue to “In Progress”. There can’t be more than 3 issues in In Progress per person.
- Once the work for the issue is done, a pull request with code changes should be linked to it and a review should be requested from another developer. Only one developer should be tagged for review.
- After that, the other developer reviews the code (as soon as possible, but in the next 24 hours), merges the pull request and moves the issue from In Progress to Ready for Testing. The merged code should be deployed to a staging server for testing.
- Finally, QA Engineer tests and checks the quality for that issue. All the discussion related to the issue is done through Github comments. If the task is not considered complete, the QA Engineer adds a comment and moves the issue back to In Progress pipeline. If the issue is considered complete, they close the issue.
Estimation is done by the entire team during the sprint planning call. The focus is on the relative sizes and complexity of tasks instead of trying to predict how much time exactly will a task take. We use points to estimate issue complexity.
For estimations, we use numbers from the Fibonacci series (1, 2, 3, 5, 8, 13, 20, 40). General guidelines are:
- 1, 2, 3 — easy
- 5 — medium
- 8 — hard
- 13, 20, 40 — very hard, need to discuss and then convert to epic and consisting of separate smaller stories
📞 Sprint review and planning call
The call consists of 2 phases:
Sprint review
- We review the last week — the work that was completed and the planned work that was not completed.
- Two main questions are asked in the Sprint Retrospective: What went well during the Sprint? What could be improved in the next Sprint?
This should take about 15 minutes.
Sprint planning
- The product owner communicates the scope of work that is intended to be done during the next sprint.
- The product owner asks the development team for estimations. Then the whole team agrees on the backlog items which might be achievable in the next sprint, resulting in a confirmed Sprint Backlog. Some product backlog items may be further split or deprioritized if the identified work is not achievable in that sprint.
This should take about 30 minutes.
👨🧑🏻 The team
- The Development Team: responsible for delivering potentially shippable increments of product at the end of each Sprint. Self-organizing and cross-functional, with all of the skills as a team necessary to create a product increment.
- Scrum Master: increases team efficiency, motivates the team, and argues for changes that will ensure quality and timeliness. Responsible for keeping time and quality requirements. Ensures that goals, scope, and product domain are understood by everyone on the team and ensures that the team has a productive work environment.
- Product Owner: defines key features of the product and success criteria. Responsible for defining stories and prioritizing the backlog of issues. Forms deadlines and release dates for the project, along with requirements and priorities.
⌨ Code deployment
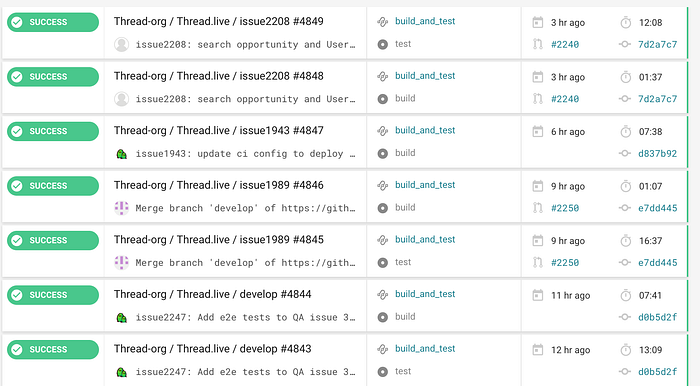
Deployment to both staging and production environments is continuous integration based. We use CircleCI as our CI tool.
- Staging — In order to deploy to the staging environment, a developer needs to create a pull request into the development branch. As soon as it’s reviewed, approved, and merged, CI will automatically run its task and do the rest.
- Staging 2 — We use another staging server to build features that are not yet ready to go live in production
- Production — Production should be synced on a weekly basis with the staging environment, and for this, a pull request must be created to merge into the master branch of the project.
🔎 Quality Assurance
Our QA process includes a constant review of the requirements, adding management of test cases, execution of regression and smoke tests, ad-hoc bug reporting, and issue verification.
Review of requirements
Whenever the product owner creates an issue, the QA team works to assure the quality of the defined issues by reviewing them. If needed, they ask questions about the issue.
When the requirements have been established, it is time to start planning and writing test cases. Test cases are created by describing the actions the QA engineer performs to make sure the piece of application functions as planned.
Once the functionality is developed, the QA engineer does ad-hoc testing and execution of test cases.
Issue testing
This includes testing the tasks that are in the Ready for Testing state, which happens when the development stage is finished. The QA engineer starts running the test cases and the main goal of this stage is to check whether the solution is developed properly from the technical perspective and meets the initial product owner’s requirements. Also, the QA engineer does ad-hoc testing to make sure the issue meets quality expectations.
When the QA engineer discovers a bug, they record it in Github and assign the product owner.
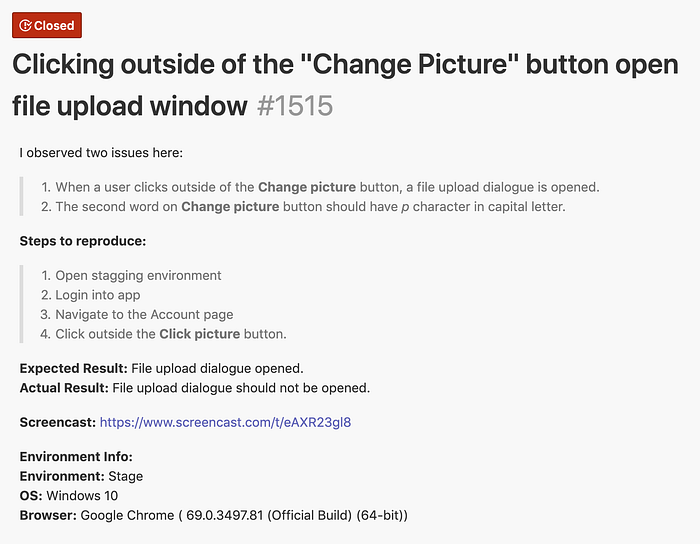
The bug reporting format:
1. Bug Title
2. Short description of the bug
3. Steps to reproduce
4. Actual Result
5. Expected Result
6. Screenshot/ Screencast
7. Regression Status
8. Environment Info
Smoke and regression tests
Smoke tests are executed after each sprint, meaning after each release. We have weekly sprints so this test is run on a weekly basis too. In this test plan, high-priority test cases are included.
With regression tests, the goal is to detect bugs in the code that were already tested previously. It is done on a monthly basis and is usually needed when adding new features or making any updates to an existing system.
First, we started doing the smoke and regression tests manually, running every week about 100 high-priority tests and the rest of the tests monthly.
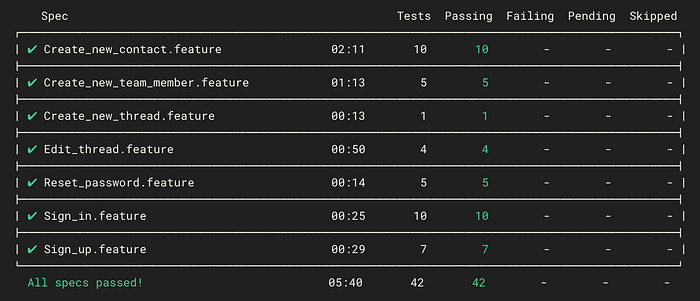
Once we set up a good process and identified all of the test scenarios, it was easy to automate the tests. Now our testing stack consists of Cypress test runner with Cucumber and Typescript to write readable and fast end-to-end tests.
The end-to-end tests run automatically after each push to any branch to help developers learn early about potential issues. Also, pushing to production is restricted if all the tests didn’t pass to make sure not to introduce any bugs during the weekly deployments.
📖 Knowledgebase
At the beginning of a project, it’s hard to feel the need to start documenting everything. But you realize that quickly pays off. Once you start changing team members and hiring, it’s great to have a good system of storing information so that the same info doesn’t need to be repeated each time.
First, we just used Dropbox Paper for defining specifications and Github Wiki to provide basic onboarding information. But once we discovered a tool called Notion, it’s where our team’s knowledge really got boosted. It’s a great app that helps to store and find any project-related information very quickly.
We use it for:
- onboarding of team members
- product specifications
- process description
- roadmap explanation
🛠 Main tools used
- GitHub — issues and bug tracking
- Zenhub — a kanban board plugin for GitHub
- Slack — the team communication
- Standup.ly — automated standup reports in Slack
- Zeplin — sharing design specifications
- Sentry — tracking code exceptions on staging and production servers
- Notion — sharing knowledge and wiki-type content
- Bitwarden — sharing credentials/passwords between team members
🎊 Conclusion
This process works pretty well for small remote teams, up to 10 members.
How do you manage remote teams? What can you take away from our example and apply to your projects? What do you have to suggest for our improvement?
Until the next read, folks.
* Need help or review of your development process? Shoot me an email.

