
I’m a huge fan of Spotify and particularly Discover Weekly. Why? It makes me feel seen. It knows my musical tastes better than any person in my entire life ever has, and I’m consistently delighted by how satisfyingly just right it is every week, with tracks I probably would never have found myself or known I would like.
Spotify is a prime example of this technology. Every Monday, over 100 million Spotify users receive a new playlist, Discover Weekly, tailored to them. This custom playlist contains around 30 songs that they have never listened to before but will probably enjoy it.
The user base goes crazy for it, which has driven Spotify to rethink its focus and invest more resources into algorithm-based playlists.
So how does Spotify do such an amazing job of choosing those 30 songs for each person each week? Let’s zoom out for a second to look at how other music services have tackled music recommendations, and how Spotify’s doing it better.

History of Online Music Curation
Back in the 2000s, Songza kicked off the online music curation scene using manual curation to create playlists for users. This meant that a team of “music experts” or other human curators would put together playlists that they just thought sounded good, and then users would listen to those playlists. (Later, Beats Music would employ this same strategy.) Manual curation worked alright, but it was based on that specific curator’s choices, and therefore couldn’t take into account each listener’s individual music taste.
Like Songza, Pandora was also one of the original players in digital music curation. It employed a slightly more advanced approach, instead manually tagging attributes of songs. This meant a group of people listened to music, chose a bunch of descriptive words for each track, and tagged the tracks accordingly. Then, Pandora’s code could simply filter for certain tags to make playlists of similar-sounding music.
Around that same time, a music intelligence agency from the MIT Media Lab called The Echo Nest was born, which took a radical, cutting-edge approach to personalized music. The Echo Nest used algorithms to analyze the audio and textual content of music, allowing it to perform music identification, personalized recommendation, playlist creation, and analysis.
Finally, taking another approach is Last.fm, which still exists today and uses a process called collaborative filtering to identify music its users might like, but more on that in a moment.
So if that’s how other music curation services have handled recommendations, how does Spotify’s magic engine run? How does it seem to nail individual users’ tastes so much more accurately than any of the other services?
Spotify’s Three Types of Recommendation Models
Spotify doesn’t actually use a single revolutionary recommendation model. Instead, they mix together some of the best strategies used by other services to create their own uniquely powerful discovery engine.
To create Discover Weekly, there are three main types of recommendation models that Spotify employs:
- Collaborative Filtering models (i.e. the ones that Last.fm originally used), which analyze both your behavior and others’ behaviors.
- Natural Language Processing (NLP) models, which analyze text.
- Audio models, which analyze the raw audio tracks themselves.
Let’s dive into how each of these recommendation models works!
Recommendation Model #1: Collaborative Filtering
First, some background: When people hear the words “collaborative filtering,” they generally think of Netflix, as it was one of the first companies to use this method to power a recommendation model, taking users’ star-based movie ratings to inform its understanding of which movies to recommend to other similar users.
After Netflix was successful, the use of collaborative filtering spread quickly and is now often the starting point for anyone trying to make a recommendation model.
Unlike Netflix, Spotify doesn’t have a star-based system with which users rate their music. Instead, Spotify’s data is implicit feedback — specifically, the stream counts of the tracks and additional streaming data, such as whether a user saved the track to their own playlist, or visited the artist’s page after listening to a song.
But what is collaborative filtering, truly, and how does it work? Here’s a high-level rundown, explained in a quick conversation:

What’s going on here? Each of these individuals has track preferences: the one on the left likes tracks P, Q, R, and S, while the one on the right likes tracks Q, R, S, and T.
Collaborative filtering then uses that data to say:
“Hmmm… You both like three of the same tracks — Q, R, and S — so you are probably similar users. Therefore, you’re each likely to enjoy other tracks that the other person has listened to, that you haven’t heard yet.”
Therefore, it suggests that the one on the right check out track P — the only track not mentioned, but that his “similar” counterpart enjoyed — and the one on the left check out track T, for the same reasoning. Simple, right?
Collaborative filtering does a pretty good job, but Spotify knew they could do even better by adding another engine. Enter NLP.
Recommendation Model #2: Natural Language Processing (NLP)
The second type of recommendation model that Spotify employs is Natural Language Processing (NLP) models. The source data for these models, as the name suggests, are regular words: track metadata, news articles, blogs, and other text around the internet.

Natural Language Processing, which is the ability of a computer to understand human speech as it is spoken, is a vast field unto itself, often harnessed through sentiment analysis APIs.
The exact mechanisms behind NLP are beyond the scope of this article, but here’s what happens on a very high level: Spotify crawls the web constantly looking for blog posts and other written text about music to figure out what people are saying about specific artists and songs — which adjectives and what particular language is frequently used in reference to those artists and songs, and which other artists and songs are also being discussed alongside them.
While I don’t know the specifics of how Spotify chooses to then process this scraped data, I can offer some insight based on how the Echo Nest used to work with them. They would bucket Spotify’s data up into what they call “cultural vectors” or “top terms.” Each artist and song had thousands of top terms that changed daily. Each term had an associated weight, which correlated to its relative importance — roughly, the probability that someone will describe the music or artist with that term.
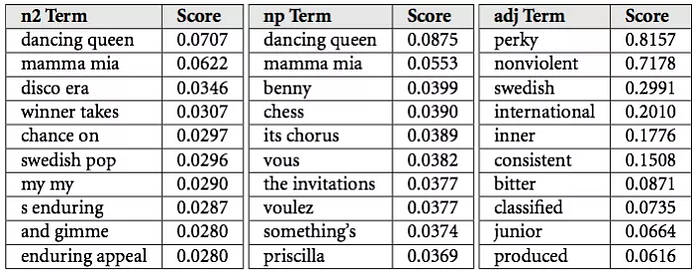
“Cultural vectors” or “top terms,” as used by the Echo Nest. Image source: How music recommendation works — and doesn’t work, by Brian Whitman, co-founder of The Echo Nest.
Then, much like in collaborative filtering, the NLP model uses these terms and weights to create a vector representation of the song that can be used to determine if two pieces of music are similar. Cool, right?
Recommendation Model #3: Raw Audio Models

First of all, adding a third model further improves the accuracy of the music recommendation service. But this model also serves a secondary purpose: unlike the first two types, raw audio models take new songs into account.
Take, for example, a song your singer-songwriter friend has put up on Spotify. Maybe it only has 50 listens, so there are few other listeners to collaboratively filter it against. It also isn’t mentioned anywhere on the internet yet, so NLP models won’t pick it up. Luckily, raw audio models don’t discriminate between new tracks and popular tracks, so with their help, your friend’s song could end up in a Discover Weekly playlist alongside popular songs!
But how can we analyze raw audio data, which seems so abstract?
With convolutional neural networks!
Convolutional neural networks are the same technology used in facial recognition software. In Spotify’s case, they’ve been modified for use on audio data instead of pixels. Here’s an example of neural network architecture:
This particular neural network has four convolutional layers, seen as the thick bars on the left, and three dense layers, seen as the more narrow bars on the right. The inputs are time-frequency representations of audio frames, which are then concatenated, or linked together, to form the spectrogram.
The audio frames go through these convolutional layers, and after passing through the last one, you can see a “global temporal pooling” layer, which pools across the entire time axis, effectively computing statistics of the learned features across the time of the song.
After processing, the neural network spits out an understanding of the song, including characteristics like estimated time signature, key, mode, tempo, and loudness. Below is a plot of data for a 30-second snippet of “Around the World” by Daft Punk.

Ultimately, this reading of the song’s key characteristics allows Spotify to understand fundamental similarities between songs and therefore which users might enjoy them, based on their own listening history.
That covers the basics of the three major types of recommendation models feeding Spotify’s Recommendations Pipeline, and ultimately powering the Discover Weekly playlist!
___
I hope you’ll enjoy reading this article.
_
Peace out

